
1. BeautifulSoup 설치
- 여기서 BeautifulSoup은 무엇인가? 예쁜 슾...? HTML 및 XML 파일에서 데이터를 가져 오기위한 Python 라이브러리입니다 어원은 '이상한 나라의 앨리스'에서 유래되었다고 하고 아름답게 정렬해준다는 정도의 의미?!
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object (unicode() in Python 2), or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str(
www.crummy.com
pip3 install bs42. 특정 URL의 HTML 데이터 가져오기(=크롤링)
- 제 블로그에 Network Category의 HTML 데이터를 가져와 Title 제목을 리스트업해보겠습니다!
context = ssl._create_unverified_context() # SSL 인증이 임시로 거쳐갈 context 필요
html = urlopen("https://eunhyee.tistory.com/category/Network", context=context)
BS_html = BeautifulSoup(html, "html.parser")3. 특정 항목 불러오기(select)
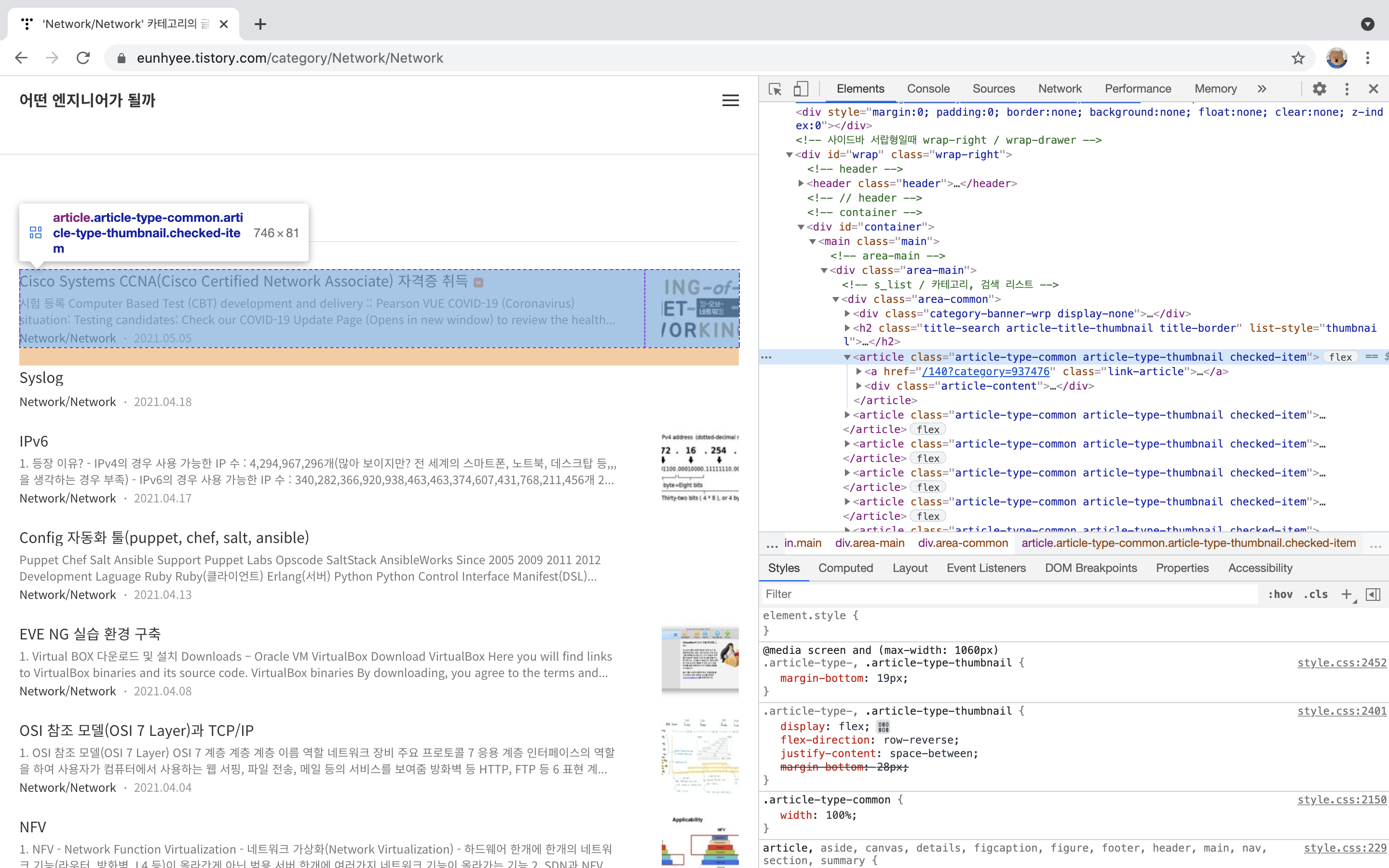
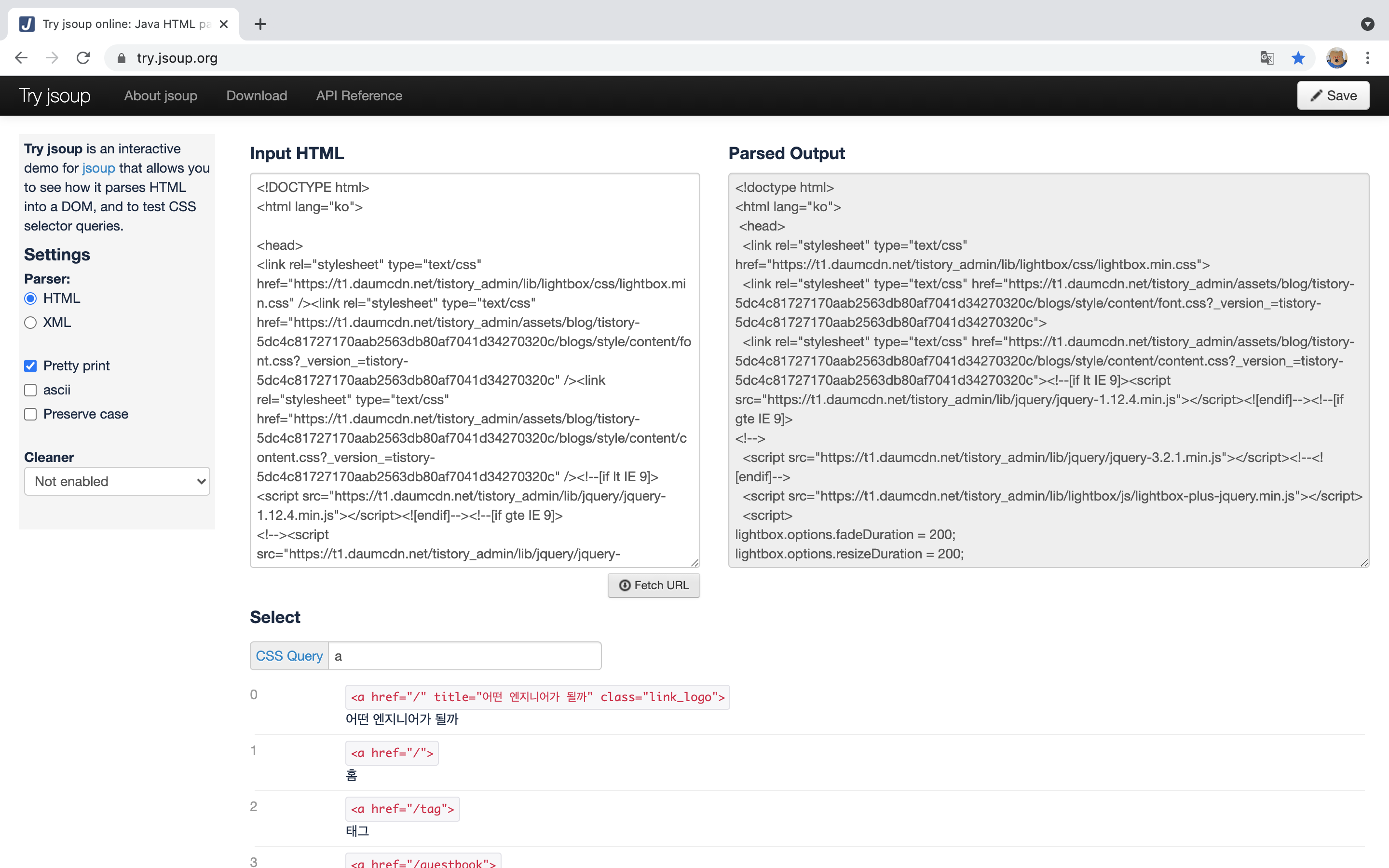
- 크롬 개발자도구와 jsoup 사이트를 통하여 필요한 데이터 추출
- div class : article-content의 a href가 각 Title의 URL이기 때문에 아래 조건으로 추출하여 list로 만듦(굳이 Title URL 추출하지 않고 해당 URL에서도 필요한 정보를 얻을 수 있지만 각 Title URL에 더 많은 정보가 있기 때문에 한번 들어가보겠습니닷)
for title in BS_html.find_all('div', {'class':'article-content'}):
url = title.select('a')[0].get('href')
url_list.append('https://eunhyee.tistory.com' + url)
Try jsoup online: Java HTML parser and CSS debugger
try.jsoup.org
4. 특정 항목 불러오기(find)
- 우선은 하나만 불러와봅시다 h2 tag는 Title URL의 제목 정보를 가지고 있으니 h2 tag를 찾고 get_text().strip()을 통하여 Title 정보만 받아오겠습니닷 (get_text().strip()를 사용하지 않을 경우에는 1 <h2 class="title-article">Cisco Systems CCNA(Cisco Certified Network Associate) 자격증 취득</h2> 요런 식으로 추출됩니다)
- 저는 제목만 불러왔지만 코드를 추가하여 더 많은 데이터를 추출할 수도 있습니다!
for index, title_url in enumerate(url_list):
html = urlopen(title_url, context=context)
BS_html = BeautifulSoup(html, "html.parser")
title = BS_html.find('h2')
title = title.get_text().strip()
print(index+1, title)
5. 결과
- 🎉 성공! 🎉
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
context = ssl._create_unverified_context()
html = urlopen("https://eunhyee.tistory.com/category/Network", context=context)
BS_html = BeautifulSoup(html, "html.parser")
url_list = []
for title in BS_html.find_all('div', {'class':'article-content'}):
url = title.select('a')[0].get('href')
url_list.append('https://eunhyee.tistory.com' + url)
for index, title_url in enumerate(url_list):
html = urlopen(title_url, context=context)
BS_html = BeautifulSoup(html, "html.parser")
title = BS_html.find('h2')
title = title.get_text().strip()
print(index+1, title)1 Cisco Systems CCNA(Cisco Certified Network Associate) 자격증 취득
2 IPv6
3 Config 자동화 툴(puppet, chef, salt, ansible)
4 EVE NG 실습 환경 구축
5 OSI 참조 모델(OSI 7 Layer)과 TCP/IP
6 PSTN, PSDN
7 정보통신망 개요
8 전송매체
9 통신의 기초
10 아날로그/디지털 신호
11 정보통신 조직
12 NFV
13 SDN
14 TCP와 UDP
15 DNS
16 Security
17 ARP Spoofing
'Programming > Python' 카테고리의 다른 글
| 문자열 다루기 (0) | 2021.08.09 |
|---|---|
| selenium 통해서 web crawling 해서 slack 메세지 보내기 (0) | 2021.06.22 |
| 파일 경로 이동(copy, move)하고 삭제(rm)하고 압축(zip)하기 (0) | 2021.06.22 |
| 파일 열고(open) 읽고(read) 쓰기(wirte) (0) | 2021.06.17 |
| OS 모듈 (0) | 2021.06.16 |